CATEGORIZATION: The Core of our Product Offering.
No system of tagging is one hundred percent accurate. Experienced human taggers often apply different tags to the same content. As tag sets grow larger and more complex, it becomes difficult for people to remember every tag that might be relevant — they tend to stick with a familiar subset, making it difficult to add new tags or change existing ones. Some content curation technology providers refer to this process as machine learning; it is more akin to the google alerts technology allowing for easy modification of key phrases by users. There really is no true machine learning taking place.
Automated taggers, on the other hand, can be overly literal in their interpretation, ignoring the context in which keywords appear. Some tagging systems require complex rules that normal end users cannot create or modify. These systems can be highly effective when configured perfectly, but they are expensive to build and maintain — their performance degrades over time because end users cannot modify what goes on inside the system’s black box.
Categorical’s technology is designed to let humans and software work together effectively. Editors are always in control, as they can see and modify any terms used by the tagger. The system makes maximum use of editor’s explicit knowledge, while also learning automatically from a set of reference documents that illustrate how terms are used in context. The interface is easy enough that anyone who can use a web search engine can successfully create and edit tags. The most important factor is to enable human-tagger cooperation to correct mistakes and improve the system going forward.
Terms and learning
The Categorical system uses words and phrases in three ways. Basic searches are exactly as one might type into a search engine or news alert system. Related terms are used to further refine tagging, by providing terms that one would expect to see, but which are too general to be used effectively as search terms. These are contrasted with negative terms, used to exclude similar but irrelevant content.
To illustrate, let’s take as an example the topic “fishing,’ in the recreational sense. “Fishing” as a basic search will yield reasonable results, as will more specific terms such as “tackle box” or “fly fishing.” To further describe the type of content we want, we could add related general terms such as “water,”, “fish,” “boat,” and “hook.” To exclude metaphorical usage, we could down weight the phrases “for a compliment” and “fishing expedition.” To exclude commercial fishing content, we could also add negative terms such as “trawler” and “cannery.”
Once the initial terms are in place, it is possible to continuously refine them by hand or automatically. The system will attempt to learn more terms of each type, and to weight them by importance. The human editor can accept, reject, or re-weight these terms in a visual interface. Editors can also add terms easily from within tagged content, by selecting words or phrases and right-clicking the mouse.
MACHINE LEARNING: Facts from Fiction.
History
Categorical’s technology is based on decades of research and implementation of research conclusions by application at top tier web sites and scientific and financial institutions.
Using that information as a starting point, Categorical worked closely with a dozen editors for more than a year watching and learning the way that editors make decisions about tagging and categorization. This understanding enables the technology to work in a way that is closer to the way human editors actually think than other systems. It is also the case, therefore, that the technology is easier for people to understand and tweak. There is no special knowledge required to set up tags; if you can search on Google, you can set up a tag.
Robust and Flexible
While Categorical’s system is easy for humans to use, this does not mean that the technology is limited or simple. In fact the opposite is true. The algorithm included in the system is very robust and performs well by tracking the human-tagger interaction. The system will provide increasingly relevant results whether the users stay close to the original set of words and phrases or expand beyond that baseline. The self-learning that is taking place by the technology is specifically designed to respond to editorial choices whether those choices remain consistent or vary over time. This capability is a significant differentiation of the Categorical technology. Unlike most other content curation technology providers, Categorical’s algorithm does result in machine learning in the truest sense of the phrase.
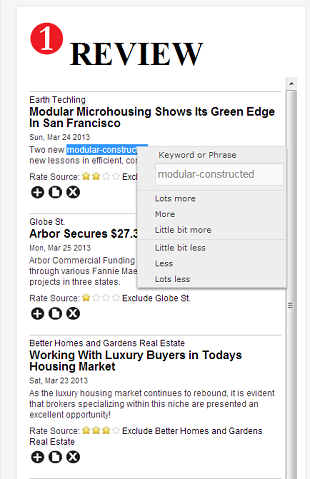
The Tagger Terms UI is set up using four term types. In the example below, the core search terms are the basic searches such as “housing trends” and “homeowner trends.” Related terms are listed in the purple colored section and help further describe the desired content. Unrelated terms such as “fashion trends” are de-emphasized in results and negative terms would exclude content with those terms. Users make the required adjustments, adding, modifying or deleting terms and weighing terms as desired in the appropriate sections.

Users can also use the system’s inline tag editing function as show below. This improves the workflow for editors as they can make changes while reading tagged content and not have to click away from the content to modify terms or adjust the weight of terms.
Analytics
In addition to empowering editors the Categorical system also provides actionable data for business lines. The technology can integrate with analytics software and provide a deep dive into the relationship between terms and revenue.
A typical analytics program used by content publishers will provide metrics related to delivered rates, open rates, clicks, click throughs, etc. These metrics may be automatically delivered or worse yet, may require manual compilation. In either event, other systems do not provide detail at the specific term level.
The Categorical system provides metrics that directly link revenue producing actions to specific tagged terms in content associated with ads. This feature provides information to the business lines in a simple to use and simple to read and understand dashboard. Publishers can use this data to make decisions about what kind of content to emphasize including what new titles will produce the greatest return on investment.